
[Paper Review] Using Question Answering Rewards to Improve Abstractive Summarization (EMNLP 2021 Findings)
Published:
QA 리워드를 통해 요약 성능 향상 시키기
Abstract
현재 abstractive summarization 분야에서는 2 가지의 어려움을 겪고 있다. 먼저 요약문이 본문의 중요한 정보를 포함하고 있지 않다는 점(Recall)과 본문에 내용과는 일치하지 않는 내용을 포함하고 있다는 점(Precision)이다. 해당 문제를 해결하기 위해 본 논문에서는 question-answering 기반 리워드를 사용한다.
Introduction
기존의 abstractive summarization 모델들이 가지고 있는 문제점인 요약문이 본문이 중요한 정보를 포함하고 있지 않다는 점과 본문과 일치하지 않는 내용을 포함하고 있다는 점은 계속해서 제기되어 왔다. Hallucination으로도 불리는 이러한 문제점을 해결하기 위해서 해당 논문에서는 question-answering (QA) 기반 리워드를 사용한다. 먼저 sequence-to-sequence (seq2seq) 요약 모델을 학습하고 precision과 recall을 개선하기 위해 QA 프레임워크를 이용한다. Precision을 향상시키기 위해서 각 생성된 요약문을 QA Generator 모델에 넣어 질문(생)과 이에 상응하는 답변(생)을 생성한다. 그 후, 생성된 질문(생)과 정답 요약문을 Qustion Answering (QA) 모델에 넣어서 나온 답변(정)과 생성된 답변(요)을 비교한다. Recall 개선을 위해서도 비슷한 방법을 사용한다. 정답 요약문을 QA Generator 모델의 입력으로 넣어 질문(정)과 답변(정)을 생성한다. 마찬가지로 생성된 질문(정)과 생성된 요약문을 QA 모델에 넣어서 나온 답변(생)을 답변(정)과 비교한다. 마지막으로 각 precision과 recall을 위한 계산된 유사도를 리워드로 주어 모델을 학습한다. 해당 논문의 contribution은 다음과 같다.
- QA 리워드를 통해 recall과 precision을 향상시켰다.
- 해당 방법을 3 가지 요약 모델에 적용했고, 2 개의 데이터 셋에 평가하였다.
- Automatic 평가와 human evaluation 모두 성능 향상을 보였다.
Method (Improving Summarization with QA Rewards)
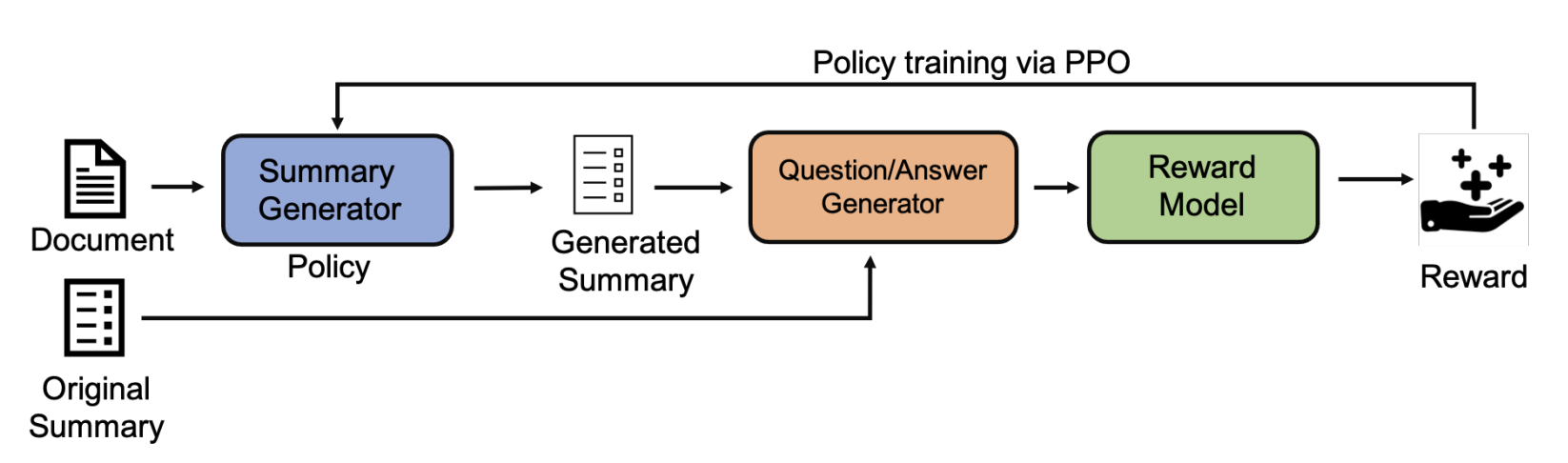
일반적으로 abstractive summarization에서는 reference summary와의 word-level 크로스 엔트로피를 최소화하는 방향으로 학습이 되지만 이러한 학습은 precision과 recall을 향상시키는데 도움이 되지 않는다. 따라서 해당 논문에서는 QA 기반 리워드와 Reinforcement 기반 학습 방법을 제안한다.
Summary Generator
본문을 seq2seq 모델의 입력으로 넣어 요약문을 token 단위로 생성한다. 평가 단계에서는 top-p nucleus 샘플링을 사용하여 디코딩한다.
Question-Answer Generator
정답 요약문을 QA Generator의 입력으로 넣어 질문(정)과 답변(정)을 생성하고, 생성된 질문(정)을 생성된 요약문과 함께 QA 모델의 입력으로 넣어 답변(생)을 생성한다. 그 후 1) 답변(정)과 답변(생)의 유사도를 비교한다. 비슷하게 생성된 요약문을 QA Generator의 입력으로 넣어 질문(생)과 답변(생)을 생성하고, 생성된 질문(생)을 정답 요약문과 함께 QA 모델의 입력으로 넣어 답변(정)을 생성한다. 그 후 2) 답변(생)과 답변(정)의 유사도를 비교한다. QA Generator 모델은 T5, QA 모델은 DistilBERT 모델을 사용한다. 해당 방법을 알고리즘으로 표현하면 다음과 같다.

Reward Model
각 답변(생, 정) 간의 유사도를 리워드로 사용한다. 만약 1)과 같이 유사도를 비교한다면 정답 요약문에 있는 답변이 생성된 요약문에도 있는 지를 평가하기 때문에 recall에 해당하는 점수가 나올 것이고 2)와 같이 유사도를 비교한다면 생성된 요약문에 있는 답변이 실제로 정답 요약문에도 있는 지를 비교하게 되기 때문에 precision에 해당하는 점수가 생성된다. 유사도는 Normalized Levenshtein distance를 사용하였다.
Policy training
Policy를 학습하기 위해서 PPO를 사용한다. PPO는 policy 학습을 할 때, 모델이 pretrained language model로 부터 너무 멀리 떨어지지 않도록 학습한다.
Evaluation and Results
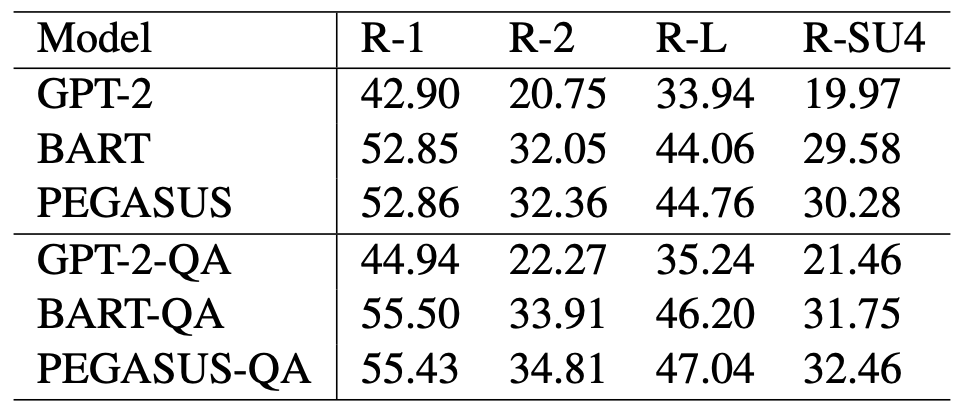
SAMSUM 데이터 셋에 평가한 결과는 위와 같다. QA 리워드를 사용하여 학습하였을 때, 모든 ROUGE 평가에서 향상하는 것을 볼 수 있다.
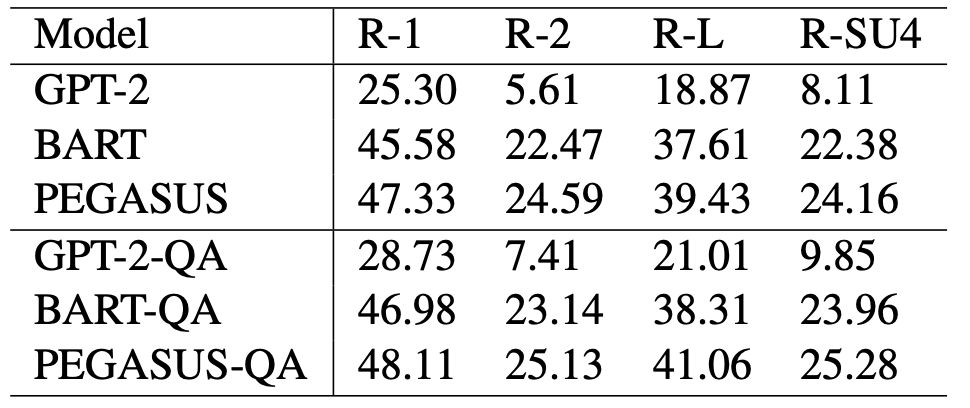
XSum 데이터 셋에 평가한 결과는 위와 같다. 마찬가지로 모든 ROUGE 평가에서 성능 향상이 이루어졌다.
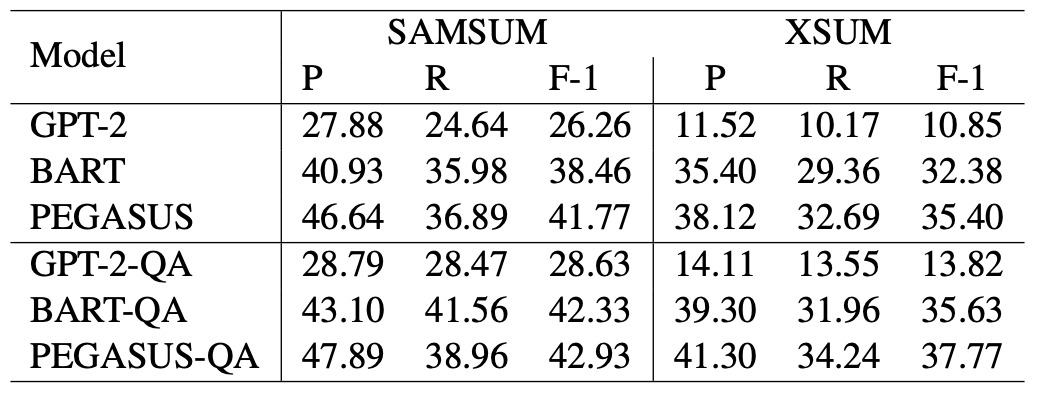
Precision과 recall 성능을 평가하기 위해서 QuestEval을 사용했다. 해당 방법은 consistency, coherence, fluency, relevance를 평가할 수 있는데, 여기서 precision은 consistency, relevance가 recall에 해당한다. 위의 표를 보면 precision과 recall 모두 성능 향상이 이루어졌다.
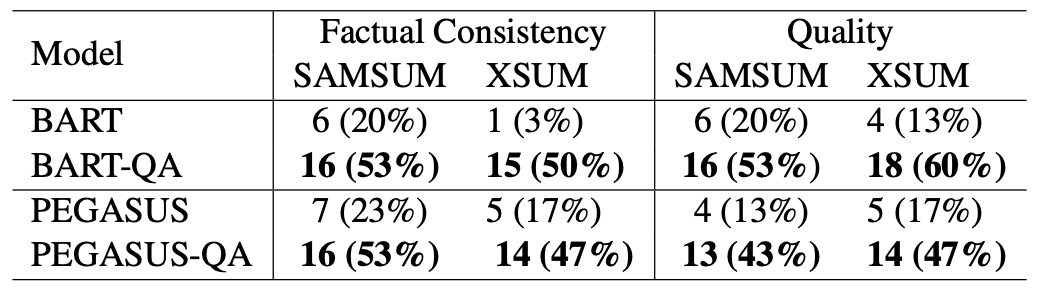
마지막으로 human evaluation 결과이다. 평가는 hallucination을 검증하는 본문과 요약문 간의 factual consistency와 요약문의 quality를 평가한다. 두 평가 방법에서 모두 성능 향상을 보였다.
Conclusion
해당 논문에서는 요약 태스크에서 낮은 recall과 precision을 개선하기 위한 방법으로 QA 기반 리워드 학습 방법을 제안한다. 해당 방법을 통해 학습한 결과 높은 ROUGE 점수를 보였고, precision과 recall을 평가하는 questEval과 human evaluation에서도 좋은 점수를 보였다.
Comment
해당 논문은 현재 요약 태스크의 문제점인 hallucination과 같은 inconsistency 문제와, 본문의 중요한 정보가 요약문에 포함되지 않는 relevance 문제를 각각 precision과 recall로써 표현한다. 이를 개선하기 위해서 QA 기반 리워드를 사용해서 좋은 성능을 보였다. 하지만 recall을 개선하기 위해 정답 요약문에서 생성된 질문을 생성된 요약문에서 답변을 찾게 되는데, 해당 방법이 실제로 효과가 있으려면 정답 요약문이 신뢰할 수 있어야 한다. 하지만 해당 논문에서 사용하는 XSum의 경우 정답 요약문의 품질이 굉장히 떨어진다고 알려져있는 데이터 셋이기 때문에 해당 방법의 신뢰성에 대해서는 의문점이 든다. 또한 모델을 설명하는 그림(Figure2)가 모델의 구조를 잘 대변하지 않고 설명이 없기 때문에 디테일한 부분이 많이 떨어진다고 생각된다.